关于FPGA来说,规划人员可以充分运用其可编程才能以及相关的东西来精确预算功耗,然后再经过优化技能来使FPGA规划以及相应的PCB板在功率方面功率更高。
静态和动态功耗及其改动
在90nm工艺时,电流走漏问题对ASIC和FPGA都变得相当严重。在65nm工艺下,这一问题更具应战性。为取得更高的晶体管功用,有必要下降阈值电压,但一起也加大了电流走漏。Xilinx公司在下降电流走漏方面做了许多尽力,尽管如此,源于走漏的静态功耗在最差和典型工艺条件下的改动依然有2:1。走漏功耗受内核电压(VCCINT)的影响很大,大约与其立方成份额,哪怕VCCINT仅上升5%,静态功耗就会进步约 15%。最终,走漏电流还与结(或芯片)温密切相关。
FPGA中静态功耗的其它来历是作业电路的直流电流,但在很大程度上,这部分电流随工艺和温度的改动不大。例如I/O电源(如HSTL、SSTL和LVDS等I/O规范的端接电压)以及LVDS等电流驱动型I/O的直流电流。有些FPGA模仿模块也带来静态功耗,但相同与工艺和温度的关系不大。例如,Xilinx FPGA中用来操控时钟的数字时钟管理器(DCM);Xilinx Virtex-5 FPGA中的锁相环(PLL);以及Xilinx FPGA中用于输入和输出信息可编程推迟的单元IODELAY。
动态功耗是指FPGA内核或I/O的开关活动引起的功耗。为核算动态功耗,有必要知道开关晶体管和连线的数量、电容和开关频率。FPGA中,晶体管在金属连线间完结逻辑和可编程互连。电容则包含晶体管寄生电容和金属互连线电容。
动态功率的公式:PDYNAMIC=nCV2f,其间,n=开关结点的数量,C=电容,V=电压摆幅,f=开关频率。
更紧凑的逻辑封装(经过内部FPGA架构改动)可以削减开关晶体管的数量。选用更小尺度的晶体管可以缩短晶体管之间的连线长度,然后下降动态功率。因而,Virtex-5 FPGA中的65nm晶体管栅极电容更小、互连线长度也更短。两者结合起来可将结点的电容减小约15%至20%,这可进一步下降动态功率。
电压关于动态功率也有影响。从90nm转向65nm工艺,只是经过将VCCINT从1.2V降至1V,Virtex-5 FPGA规划的动态功率就下降了约30%。再加上结构增强带来的功率下降,总的动态功耗比90nm技能时下降达40%至50%。
(注:动态功率与VCCINT的平方成正比,但关于FPGA内核来说基本上与温度和工艺无关。)
运用FPGA规划技能下降功耗
Xilinx公司供给了两款功率剖析东西。XPower Estimator (XPE)电子数据表东西可在规划人员运用物理施行东西前运用。在规划物理施行完结后,则可以选用第二款东西XPower Analyzer来查看所做的改动对功耗的影响。
下降功耗的一种办法便是为规划挑选最适用的FPGA,然后运用其可编程才能进一步优化规划的功耗。正确的规划挑选会一起改进静态和动态功耗。
源于走漏电流的静态功率正比于逻辑资源的数量,也便是说正比于结构特定FPGA所运用的晶体管数量。因而,假如削减所运用的FPGA资源,选用更小的器材完结规划,那么就可以下降静态功耗。
可以选用多种办法来下降规划的规划,最基本的一种技巧便是逻辑功用分时。也便是说,假如两组电路完结一组线性功用,而且互相完全相同,那么就可以只用一组电路但将速率进步一倍来完结相同的功用。这样需求的逻辑资源就削减了一半。
另一种缩小逻辑规划的办法是运用Xilinx FPGA的部分重装备功用,当两部分电路不一起作业时,可以在某个时刻段将某部分电路重新装备完结另一种电路功用。
一起,还可以将功用移动到不太受限制的资源,例如,将状态机转移到BRAM、或许将计数器转移到DSP48模块、寄存器转移到移位寄存器逻辑,以及将BRAM转移到查找表RAM(LUTRAM)。一起还可以确保不要让规划的时序太紧张,因为那样会需求更多的逻辑和寄存器。
此外,还应当充分发挥FPGA架构中集成的硬IP块(BRAM、DSP、FIFO、Ethernet MAC、PCI Express)的长处。
下降静态功率的另一个办法是细心查看规划,防止冗余的直流耗费源。规划中经常会运用到具有剩余或躲藏DCM或PLL的模块,这种状况可能在模块规划后忘掉将剩余的资源去除,或许在构建下一代产品时运用了一些留传代码。将DCM或PLL笼统到规划的顶层,这样模块之间就可以共享资源,然后可进一步减小规划的规划并下降直流功率。
更好地运用存储器模块也可协助下降FPGA规划的动态功耗,然后进一步下降整体功耗。因为动态功耗是容抗(面积或长度)和频率的函数,因而应当查看规划中拜访块存储器的办法并确认可以对容抗和频率进行优化的区域。
Xilinx FPGA供给两种类型的存储器阵列。18Kbit或36Kbit的BRAM是针对大存储器模块而优化的。LUTRAM根据FPGA中的查找表,是针对细粒度存储而优化的。Xilinx Virtex-5 FPGA中,LUTRAM的单位是64bit。
在这两种类型中,BRAM一般功耗要大一些。启用后的BRAM静态功率是其功耗的最大部分,跳变带来的功耗居于第二位。规划人员可以采纳一些过程来优化BRAM的功耗。例如,可以仅在读或写周期才启用BRAM。关于较小的存储器模块可以运用LUTRAM来替代BRAM,将 BRAM留给较大的存储器模块运用。此外,还可以测验将BRAM用于多个大型模块。另一种技能是合理组织存储器阵列来削减其占用的推迟面积、使功用最大化并尽量下降其功耗。图1左边给出了一个针对速度和面积而优化的2K x 36bit存储阵列。
咱们运用四个2K x 9bit模块并行构成这一存储阵列,并在需求新值时启用(Enable)一切四个模块。另一办法是选用四个512 x 36bit模块来组织2K x 36bit,但运用低两位地址解码来挑选拜访哪个512 x 36bit模块。在后一种状况下,某个时刻仅拜访一个存储器块,功耗将比榜首种办法下降75%。
图1右侧显现的是Xilinx公司的块存储器生成器(Block Memory Generator),运用它可以生成恣意巨细的存储器阵列并可以针对速度或功率对其进行优化。图2则给出了详细运用中的Xilinx Power EsTImator,比较了在给定的使能速率下N个模块一起发动与N/4模块发动时的功耗状况。成果显现动态功率下降了75%。
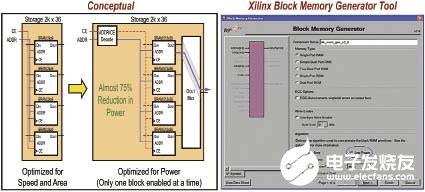
图1 速度和面积与功率优化存储器阵列(左)
以及Xilinx Block Memory Generator与功率面积挑选(右)
Xilinx东西可协助挑选合适的存储器阵列。考虑某个规划中需求两组存储器区域。一种状况下需求运行在300MHz的16组64 x 32bit存储器结构(总位数为32K),另一种状况下需求16组512 x 36bit 存储器架构 (总位数为294K)。
看一下16组64 x 32bit存储器结构的功率比较,XPE东西显现出小存储器阵列最好用LUTRAM来完结,这样比用BRAM节省85%的功耗(如图3)。这是因为假如选用BRAM的话,只能用16个18K位的模块来完结16个极小(64 x 32bit)的存储器,有许多空间被浪费了。而第二种状况16组18K位阵列的功率比较,XPE显现状况正好相反,应当选用大一些的存储器阵列来完结(图 4)。这种状况下,选用BRAM比选用LUTRAM可以节省28%的功耗,这是因为假如选用LUTRAM就需求启用更多的小粒度目标并添加更多的互连。
Xilinx FPGA的时钟门控功用
Xilinx FPGA的时钟门控功用供给了一些十分有意思的用处。例如,可以运用BUFGMUX时钟缓冲器将FPGA内的某个大局时钟封闭,或许动态挑选较慢的时钟。还可以运用BUFGCE时钟缓冲器进行按时钟周期(cycle-by-cycle)的门控,与ASIC规划中运用的时钟门控技能相似。规划中可以一起运用这两种功用。
在某些规划中,一些模块并非一向运用,但关于功耗影响却很大,此刻这些办法十分有用。可以时钟周期为根底或许按多个时钟周期的组合敞开或封闭可能有不计其数个负载的大型时钟域。

图2 XPE功率优化阵列成果

图3 运用块RAM 或 LUTRAM完结小存储器阵列的功率预算
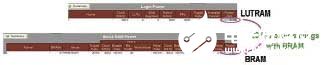
图4 运用LUTRAM和块RAM完结大存储器阵列的功率预算
在电路板一级下降功耗
PCB规划师、机械工程师和体系架构师在电路板一级可以考虑经过几个方面来下降FPGA的功耗,FPGA的内核电压和结温关于功耗的不同方面都有很强的影响。
操控VCCINT内核电压是板级下降功耗的一种办法。源于走漏的静态功耗以及动态功耗都高度依赖于FPGA的内核电压。因而,削减走漏的一种办法便是将内核电压设置在挨近额定值(1V)的当地,而不是作业在Virtex-5电压规模的高端(1.05V = +5%)。
选用现代开关稳压器,可以取得±1.5%的电压安稳度,而不是规范的±5%规范。坚持内核电压在1V(而不是最大值 1.05V),可将走漏导致的静态功耗下降15%,一起动态功耗下降10%。
下降FPGA结温的一种简略显着的办法是运用散热更好的PCB或散热器。然后,FPGA规划人员只需可以下降功耗的改动都是值得鼓舞的。在结温100℃左右时,15℃的温度下降可以将源于走漏导致的静态功耗下降20%。
经过监控FPGA中的温度和电压也可以下降功耗。Virtex-5 FPGA中包含了一个称为System Monitor的模仿模块,可以监控外部和内部模仿电压以及芯片内部温度。System Monitor根据一个10位的A/D变换器,可以在-40℃至+125℃规模内供给精确牢靠的丈量成果。A/D变换器将片上传感器的输出数字化,可以运用它来监控多达17路外部模仿输入,然后监控体系功用与外部环境。模块内包含了可装备的阈值和告警电平,而且可以在可装备的寄存器内存储丈量成果,因而可方便地接口到用户逻辑或微处理器。
此外,I/O功率成为在功耗和功用平衡过程中需求考虑的另一重要因素,经过更为优化的I/O挑选可以进一步下降整体功耗。关于输出来说,驱动力气最大的规范所消费的功率也最大,因而功率随输出使能速率和跳变速率线性改动。但是,LVDS是个破例,因为它选用了独立于跳变速率的根据固定电流源。关于输入来说,参阅规范消费功率也较大,因为它们需求完结差分接收器而且需求可挑选的内部端接。两者都需求消费直流功率。
因为端接一般需求消费很多功率,因而运用时需谨慎考虑功率和功用的平衡。选用外部接口或不需求端接的计划会大大下降功耗。
总结
Xilinx公司一向致力于在ISE套件东西中集成功率优化技能,一起,还可以将ISE装备为功率优化归纳引擎来主动定位源代码中的小阵列并将其归纳进LUTRAM中。
最近,Xilinx公司还推出了一个优化布局器,可以将功用进行分组,然后最小化布线间隔和容抗。称为PlanAhead 的一组相关东西可以将逻辑资源分组并从物理上在FPGA内进行大略的面积预算和方位定位,这样就可以削减电容并加速布线速度。
Xilinx预期FPGA的动态和静态功率将会持续面对应战,所以将持续致力于优化FPGA的功率管理东西和规划办法,一起也将不断尽力在芯片层面上处理功耗问题。
责任编辑:gt