凭仗超卓的功能和功耗目标,赛灵思 FPGA 成为规划人员构建卷积神经网络的首选。新的软件东西可简化完结作业。
人工智能正在阅历一场革新,这要得益于机器学习的快速前进。在机器学习范畴,人们正对一类名为“深度学习”算法发生稠密的爱好,由于这类算法具有超卓的大数据集功能。在深度学习中,机器能够在监督或不受监督的办法下从许多数据中学习一项使命。大规模监督式学习已经在图画辨认和语音辨认等使命中取得巨大成功。
深度学习技能运用许多已知数据找到一组权重和偏差值,以匹配预期成果。这个进程被称为练习,并会发生大型形式。这鼓励工程师倾向于运用专用硬件(例如 GPU)进行练习和分类。
跟着数据量的进一步添加,机器学习将转移到云。大型机器学习形式完结在云端的 CPU 上。虽然 GPU 对深度学习算法而言在功能方面是一种更好的挑选,但功耗要求之高使其只能用于高功能核算集群。因而,亟需一种能够加快算法又不会明显添加功耗的处理渠道。在这样的布景下,FPGA 似乎是一种抱负的挑选,其固有特性有助于在低功耗条件下轻松发动许多并行进程。
让咱们来具体了解一下如安在赛灵思 FPGA 上完结卷积神经网络 (CNN)。CNN 是一类深度神经网络,在处理大规模图画辨认使命以及与机器学习相似的其他问题方面已大获成功。在当时事例中,针对在 FPGA 上完结 CNN 做一个可行性研究,看一下 FPGA 是否适用于处理大规模机器学习问题。
卷积神经网络是一种深度神经网络 (DNN),工程师最近开端将该技能用于各种辨认使命。图画辨认、语音辨认和自然语言处理是 CNN 比较常见的几大运用。
什么是卷积神经网络?
卷积神经网络是一种深度神经网络 (DNN),工程师最近开端将该技能用于各种辨认使命。图画辨认、语音辨认和自然语言处理是 CNN 比较常见的几大运用。
2012 年,Alex Krishevsky 与来自多伦多大学 (University of Toronto) 的其他研究人员 [1] 提出了一种依据 CNN 的深度架构,赢得了当年的“Imagenet 大规模视觉辨认应战”奖。他们的模型与竞争对手以及之前几年的模型比较在辨认功能方面取得了实质性的提高。自此,AlexNet 成为了全部图画辨认使命中的比照基准。
AlexNet 有五个卷积层和三个细密层(图 1)。每个卷积层将一组输入特征图与一组权值滤波器进行卷积,得到一组输出特征图。细密层是彻底相连的一层,其间的每个输出均为全部输入的函数。
卷积层
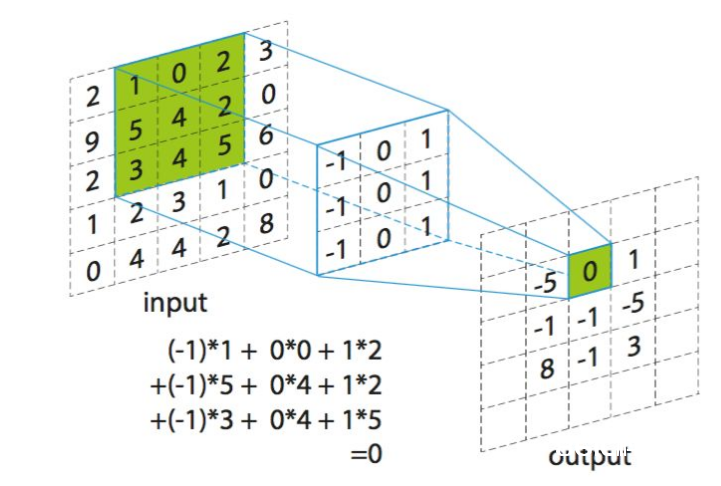
AlexNet 中的卷积层担任三大使命,如图 2 所示:3D 卷积;运用校对线性单元 (ReLu) 完结激活函数;子采样(最大池化)。3D 卷积可用以下公式表明:
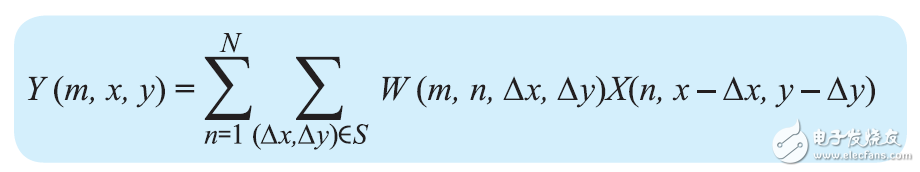
其间Y (m,x,y) 是输出特征图 m 方位 (x,y) 处的卷积输出,S 是 (x,y) 周围的部分邻域,W 是卷积滤波器组,X(n,x,y)是从输入特征图 n 上的像素方位 (x,y) 取得的卷积运算的输入。
所用的激活函数是一个校对线性单元,可履行函数 Max(x,0)。激活函数会在网络的传递函数中引进非线性。最大池化是 AlexNet 中运用的子采样技能。运用该技能,只需挑选像素部分邻域最大值传播到下一层。
界说细密层
AlexNet 中的细密层相当于彻底衔接的层,其间每个输入节点与每个输出节点相连。AlexNet 中的第一个细密层有 9,216 个输入节点。将这个向量乘以权值矩阵,以在 4,096 个输出节点中发生输出。鄙人一个细密层中,将这个 4,096 节点向量与另一个权值矩阵相乘得到 4,096 个输出。最终,运用 4,096 个输出经过 softmax regression 为 1,000 个类创立概率。
在 FPGA 上完结 CNN
跟着新式高档规划环境的推出,软件开发人员能够更方便地将其规划移植到赛灵思 FPGA 中。软件开发人员可经过从 C/C++ 代码调用函数来充分运用 FPGA 与生俱来的架构优势。Auviz Systems 的库(例如 AuvizDNN)可为用户供给最佳函数,以便其针对各种运用创立定制 CNN。可在赛灵思 SD-Accel™ 这样的规划环境中调用这些函数,以在 FPGA 上发动内核。
最简略的办法是以次序办法完结卷积和向量矩阵运算。考虑到所触及核算量,因而次序核算会发生较大时延。
次序完结发生很大时迟的主要原因在于 CNN 所触及的核算的肯定数量。图 3 显现了 AlexNet 中每层的核算量和数据传输状况,以阐明其复杂性。
因而,很有必要选用并行核算。有许多办法可将完结进程并行化。图 6 给出了其间一种。在这里,将 11×11 的权值矩阵与一个 11×11 的输入特征图并行求卷积,以发生一个输出值。这个进程触及 121 个并行的乘法-累加运算。依据 FPGA 的可用资源,咱们能够并行对 512 抑或 768 个值求卷积。
为了进一步提高吞吐量,咱们能够将完结进程进行流水线化。流水线能为需求一个周期以上才干完结的运算完结更高的吞吐量,例如浮点数乘法和加法。经过流水线处理,第一个输出的时延略有添加,但每个周期咱们都可取得一个输出。
运用 AuvizDNN 在 FPGA 上完结的完好 CNN 就像从 C/C++ 程序中调用一连串函数。在树立目标和数据容器后,首要经过函数调用来创立每个卷积层,然后创立细密层,最终是创立 softmax 层,如图 4 所示。
AuvizDNN 是 Auviz Systems 公司供给的一种函数库,用于在 FPGA 上完结 CNN。该函数库供给轻松完结 CNN 所需的全部目标、类和函数。用户只需求供给所需的参数来创立不同的层。例如,图 5 中的代码片段显现了怎么创立 AlexNet 中的第一层。
AuvizDNN 供给装备函数,用以创立 CNN 的任何类型和装备参数。AlexNet 仅用于演示阐明。CNN 完结内容作为完好比特流载入 FPGA 并从 C/C++ 程序中调用,这使开发人员无需运转完结软件即可运用 AuvizDNN。
FPGA 具有许多的查找表 (LUT)、DSP 模块和片上存储器,因而是完结深度 CNN 的最佳挑选。在数据中心,单位功耗功能比原始功能更为重要。数据中心需求高功能,但功耗要在数据中心服务器要求限值之内。
像赛灵思 Kintex® UltraScale™ 这样的 FPGA 器材可供给高于 14 张图画/秒/瓦特的功能,使其成为数据中心运用的抱负挑选。图 6 介绍了运用不同类型的 FPGA 所能完结的功能。
全部始于 c/c++
卷积神经网络备受喜爱,并大规模布置用于处理图画辨认、自然语言处理等许多使命。跟着 CNN 从高功能核算运用 (HPC) 向数据中心搬迁,需求选用高效办法来完结它们。
FPGA 可高效完结 CNN。FPGA 的具有超卓的单位功耗功能,因而十分适用于数据中心。
AuvizDNN 函数库可用来在 FPGA 上完结 CNN。AuvizDNN 能下降 FPGA 的运用复杂性,并供给用户可从其 C/C++ 程序中调用的简略函数,用以在 FPGA 上完结加快。运用 AuvizDNN 时,可在 AuvizDNN 库中调用函数,因而完结 FPGA 加快与编写 C/C++ 程序没有太大差异。
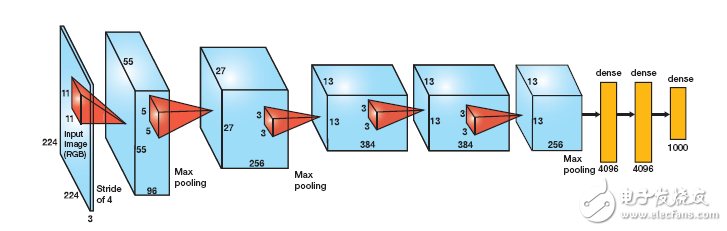
图 1 – AlexNet 是一种图画辨认基准,包括五个卷积层(蓝框)和三个细密层(黄)。

图 2 – AlexNet 中的卷积层履行 3D 卷积、激活和子采样。
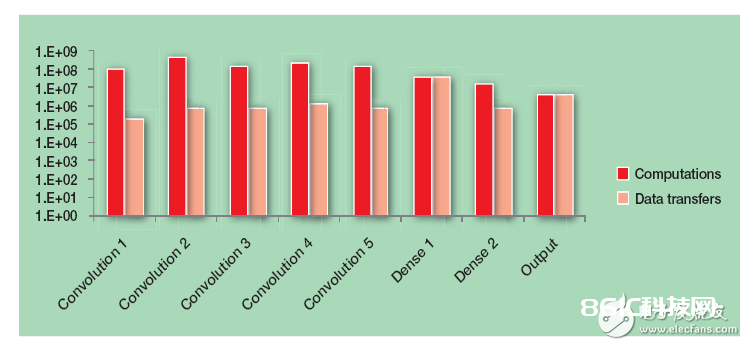
图 3 – 图表展现了 AlexNet 中触及的核算复杂性和数据传输数量。

图 4 – 完结 CNN 时的函数调用次序。

图 5 – 运用 AuvizDNN 创立 AlexNet 的 L1 的代码片段。
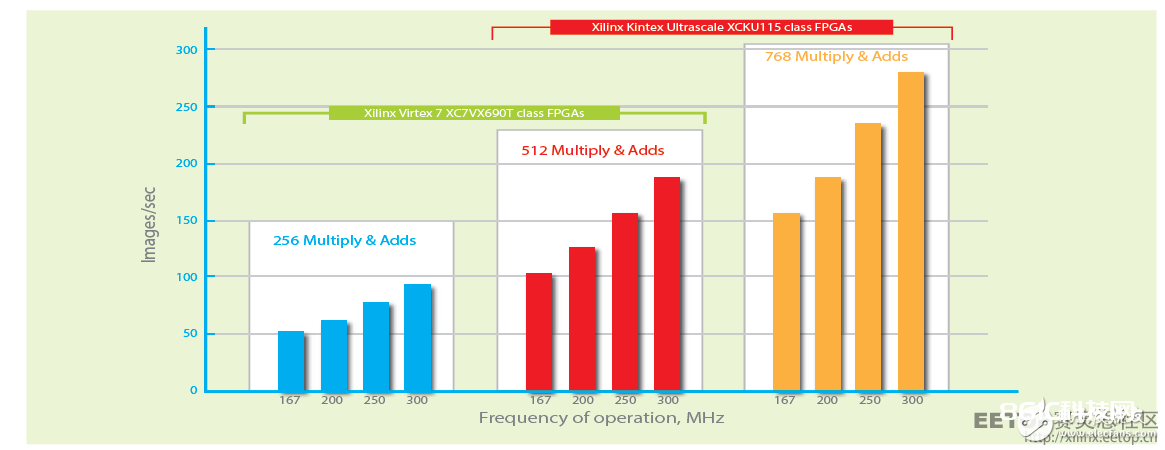
图 6 – AlexNets 的功能因 FPGA 类型不同而不同。