1. 多线程编程的应战
迄今,处理器技能范畴中的立异现已使得核算机具有了作业于更高时钟速率的中央处理器单元(CPU)。可是,跟着时钟速率迫临其理论上的物理极限,具有多个(而不是单个)处理核的新式处理器正处于研制之中。运用这些新式多核处理器,自动化测验运用运用并行编程技能,便能够到达最佳功能和最高吞吐量。Edward Lee博士——加州大学伯克利分校电气与核算机工程系的出色教授——这样描绘并行处理的技能优势:
“许多技能专家预言,回应摩尔定律的完结的将是日趋并行的核算机架构。假如咱们期望继续前进核算功能,核算机程序有必要能够运用这种并行机制。”
并且,运用多核处理器的编程运用是一个巨大的编程应战,这是广为承受的。比尔盖茨——微软公司的缔造者——关于这一应战有这样一段话:
“要想充分运用并行作业的处理器的威力,…软件有必要能够处理并发性问题。但正如任何一位编写过多线程代码的开发者告知你的那样,这是编程范畴最艰巨的使命之一。”
走运的是,LabVIEW为多核处理器供给了一个抱负的编程环境,由于它为创立并行算法供给了一个直观的环境,并且它能够动态指使多个线程至一项给定的运用。事实上,运用多核处理器的自动化测验运用,能够方便地被优化以获取最佳功能。并且,PXIe模块化仪器增强了这一技能优势,由于PCIe总线使高数据传输速率成为或许。从多核处理器和PXIe仪器的两个详细运用是:多通道信号剖析和线上处理(硬件在环)。在本文的后续部分,咱们将评价各种并行编程技能,并描写每项技能所带来的功能优势。
至页首
2. 完结并行测验算法
得益于并行处理的一项常见自动化测验运用(ATE),就是多通道信号剖析。由于频率剖析是一项占有处理器较多的操作,经过并行化处理测验代码使得每个通道的信号处理被分配至多个处理器核,能够前进履行速度。从编程人员的视点来看,为取得这一技能优势,所需的仅有改动就是只是重构测验算法。
为描绘这一进程,咱们将比较用于多通道频率剖析(傅立叶改换或FFT)的两个算法的履行时刻,它们别离坐落一个高速数字化仪的两个通道上。在该测验中,咱们运用PXIe-5122 14-位高速数字化仪的两个通道,以最高采样率(100 MS/s)收集信号。首要,咱们这一操作在LabVIEW中的传统的次第编程模型。
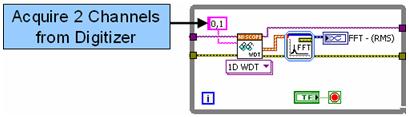
图1。运用次第履行的LabVIEW代码
在上述模块框图中,两个通道的频率剖析均在一个FFT快速VI中完结,它次第剖析每个通道信号。尽管上述算法也能够在多核处理器中有用履行,但仍存在经过并行处理每个通道前进算法功能的或许。
假如咱们剖析上述算法,咱们会发现完结FFT所需的时刻要比从高速数字化仪收集数据长得多。经过每次获取一个通道的数据并并行履行两次FFT,咱们能够显着下降处理时刻。下图表明了一个选用并行办法的新的LabVIEW模块框图。
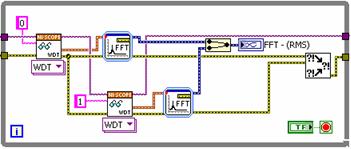
图2。运用并行履行的LabVIEW代码
如上面代码所示,将次第获取数字化仪的每个通道的数据。留意,假如两次数据获取均来自不同的仪器,那么完全能够并行完结这些操作。可是,由于傅立叶改换占用很多的处理器时刻,咱们仍能够仅经过将信号处理并行化改善功能。故而减少了总的履行时刻。两种完结的履行时刻如下所示:
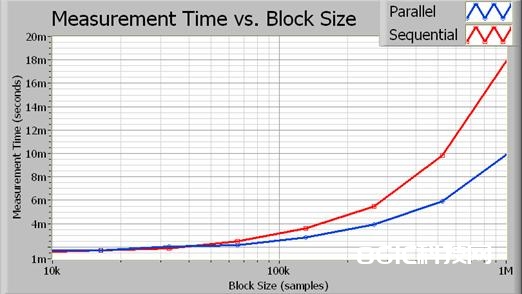
图3。次第算法与并行算法(时刻)的履行时刻比较
如上图所示,跟着数据块巨细(每次获取的采样数)的增加,经过并行处理节省的处理时刻愈为显着。事实上,关于更大的数据块,并行算法完结近2倍的功能改善。下图描绘了功能增加的准确百分比随收集数据块巨细(以采样数为单位)的改变。
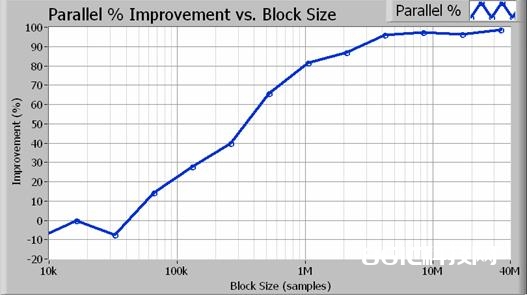
图4。并行算法带来的功能增加(百分比)
图4显现,当数据块大于1百万采样(100 Hz精度带宽)时,并行办法完结80%或更高的功能增加。
在多核处理器之上,咱们能够方便地完结自动化测验运用的功能改善,由于LabVIEW动态地分配每一个线程。事实上,用户不需求创立特别的代码以支撑多线程,而是经过最少的编程调整,并行测验运用便能够获益于多核处理器。
3. 装备定制的并行测验算法
将信号处理并行化的技能优势在于它支撑LabVIEW在多个处理器核中区分CPU的费用。鄙人图中,咱们描绘了CPU处理算法每一部分的次第。
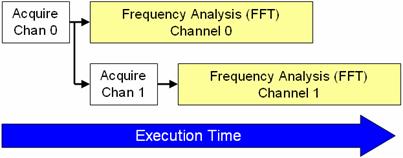
图5。CPU的处理履行
如图所示,LabVIEW能够并行处理许多收集数据,然后节省了履行时刻。关于LabVIEW,并行处理的需求之一就是复制(或克隆)每个信号处理子例程。缺省状况下,LabVIEW的许多信号处理算法装备为“重入履行”。这就意味着LabVIEW将动态分配每个子例程的一个不同实例,包含独立线程和存储空间。因此,定制子例程有必要被装备为作业于重入办法。这能够经过LabVIEW中一个简略的装备过程完结。欲设置这一特点,挑选文件菜单下VI特点并选中“履行”栏;然后,选中“重入履行”符号(如下所示)。
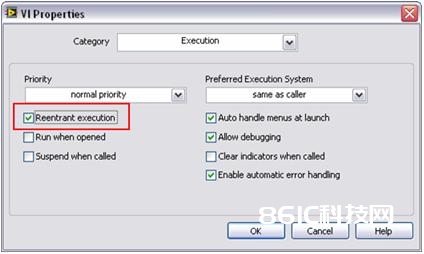
图6。在LabVIEW中装备重入履行特点
经过上图所示的简略过程,咱们能够并行履行多个定制子例程,就好像规范LabVIEW剖析函数那样。因此,在多核处理器之上,自动化测验运用经过简略的编程技能就能够完结功能的改善。
4. 优化硬件在环运用
得益于并行信号处理技能的又一个运用就是为一起输入与输出运用多个仪器。一般,这些运用被称为硬件在环(HIL)或在线处理运用。在此场景下,高速数字化仪或高速数字I/O模块用于信号收集,其软件履行数字信号处理算法。最终,经过另一个模块化仪器生成成果。其典型模块框图如下所示:

图7。在线信号处理(HIL)模块框图
常见HIL运用包含在线数字信号处理(滤波、插值等)、传感器仿真和定制组件模仿。在这篇特别预备的白皮书中,咱们将探求用于在在线数字信号处理运用中取得最佳吞吐量的技能。
一般能够运用两种根本的编程结构,单循环结构和带有行列的管道式多循环结构。单循环结构完结简略,关于小数据块具有低时延。相比之下,多循环结构能够支撑高得多的吞吐量,由于它们能够更好地运用多核CPU。
关于传统的单循环办法,一个高速数字化仪的读函数、信号处理算法和高速数字I/O依次安排。如下面模块框图所示,这些子例程中的每一个都有必要依照LabVIEW数据流编程模型确认的次第履行。

图8。在循环中依单循环办法进行处理
单循环结构受限于几个要素。由于次第履行每一环节,处理器在处理数据的一起受限无法履行仪器I/O。在这种办法下,由于处理器一次只能履行一个函数,所以无法有用运用多核CPU。因此,在运用中仅运用了多核CPU的一个核。尽管单循环结构足以处理较低的收集速率,可是要想得到较高的数据吞吐量仍需求选用多循环办法。
多循环架构运用行列结构完结while循环间的数据传递。下面,咱们打开论说在while循环间选用一个行列结构进行数据流编程的概念。
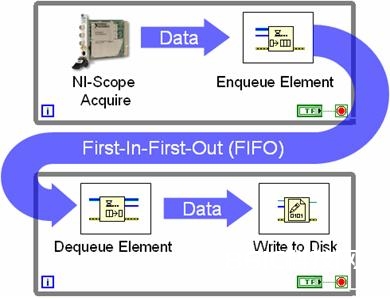
图9。行列结构支撑多循环间的数据同享
如图所示,行列支撑多个循环间的数据同享。上图所表明的是典型的所谓生产者/顾客循环结构。这儿,在一个循环中,一个高速数字化仪继续收集数据,并在每次迭代中将新的数据集传递至FIFO行列。顾客循环仅需监督行列的状况,当每个数据集可用时将其写入磁盘。选用行列的含义在于这两个循环均可彼此独立履行。在上例中,高速数字化仪能够继续收集数据,即便这些数据写入磁盘时存在必定的推迟。与此一起,其它的采样仅需存储在FIFO行列中。一般,生产者/顾客管道式办法,经过支撑更有用的处理器运用率,使更高的数据吞吐量成为或许。这一技能优势在多核处理器中乃至更为显着,由于LabVIEW能够动态分配CPU线程至每个处理器核。
关于一项在线信号处理运用,咱们能够运用三个独立的while循环和两个行列结构,完结其间的数据传递。在此运用场景下,一个循环将从一台仪器收集数据,一个循环将专门履行信号处理,而第三个循环将数据写入到另一台仪器。描绘这一办法的LabVIEW模块框图如下所示:
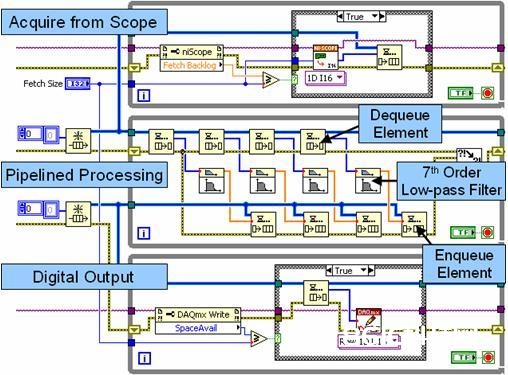
图10。具有多个循环和排队结构的管道式信号处理
在上图中,最上面的循环是一个生产者循环,它从一个高速数字化仪收集数据,并将其传递至第一个行列结构(FIFO)。中心的循环一起作为生产者和顾客作业。每次迭代中,它从行列结构中卸载(消费)若干个数据集,并以管道的办法独立对其进行处理。这种管道办法经过支撑高达四个数据集的独立处理,完结了多核处理器环境下的功能改善。留意,中心的循环一起也作为一个生产者作业,将处理后的数据传递至第二个行列结构。最终,最下面的循环将处理后的数据写入至高速数字I/O模块。
并行处理算法改善了多核CPU的处理器运用率。事实上,总吞吐量有赖于两个要素,处理器运用率和总线传输速度。一般,CPU和数据总线在处理大数据块时作业功率最高。并且,咱们能够进一步运用具有更快传输速度的PXIe仪器,减缩数据传输时刻。因此,咱们经过依收集数据巨细(以采样数计)改变的采样率描绘最大吞吐量,如下所示:
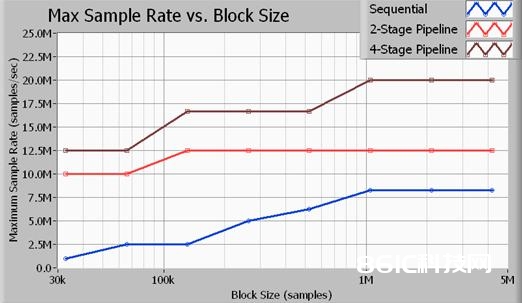
图11。多循环结构与单循环结构的吞吐量比较
该图中所描绘的一切标定都是环绕16-位采样进行的。此外,所选用的信号处理算法为一个到频率为采样率的0.45倍的7阶巴特沃兹低通滤波器。如数据显现,4阶段管道式(多循环)办法支撑最大数据吞吐量。留意,2阶段信号处理办法取得了比单循环办法(次第)更好的功能,但其CPU的运用不及4阶段办法有用。上面所列的采样率为PXIe-5122高速数字化仪和PXIe-6537高速数字I/O模块的输入和输出的最大采样率。留意,当采样率为20 MS/s时,运用总线的输入和输出的数据传输率均为40 MB/s,所以总的总线带宽为80 MB/s。
应当考虑的是,管道式处理办法在输入与输出之间的确引进了时延。所引进的时延取决于几个要素,包含数据块的巨细和采样率。下表比较了单循环和4阶段多循环架构中实测所得的时延随数据块巨细和最大采样率的改变状况。
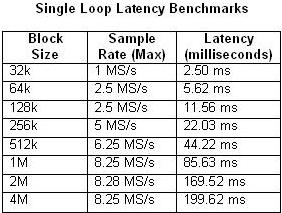
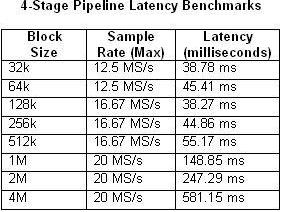
表1和2。单循环和4阶段管道的时延标定
正如人们能够预知的,当CPU的运用率挨近100%不时延也随之增加。这一点在采样率为20 MS/s的4阶段管道典范中尤为显着。相比之下,任何一个单循环典范的CPU运用率都简直不会超越50%。
5. 总结
根据PC的仪器体系,如PXI和PXIe模块化仪器,从多核处理器技能的前进和数据总线速度的前进中获益匪浅。当新式CPU经过增加多个处理核改善功能时,并行或管道式处理结构成为最大化CPU功率所必需。走运的是,LabVIEW经过将处理使命动态分配至单个处理核;为这一编程应战供给了一种上佳的解决方案。如上面数据显现,将LabVIEW算法结构化以运用并行处理,能够带来显着的功能前进。