1 导言
机器人听觉体系首要是对人的声响进行语音辨认并做出判别,然后输出相应的动作指令操控头部和手臂的动作,传统的机器人听觉体系一般是以PC机为渠道对机器人进行操控,其特色是用一台计算机作为机器人的信息处理中心经过接口电路对机器人进行操控,尽管处理才能比较强壮,语音库比较齐备,体系更新以及功用拓宽比较简单,可是比较粗笨,不利于机器人的小型化和杂乱条件下进行作业,此外功耗大、本钱高。
本次规划选用了性价比较高的数字信号处理芯片TMS320VC5509作为语音辨认处理器,具有较快的处理速度,使机器人在脱机状况下,独立完结杂乱的语音信号处理和动作指令操控,FPGA体系的开发降低了时序操控电路和逻辑电路在PCB板所占的面积,使机器人的”大脑”的语音处理部分微型化、低功耗。一个体积小、低功耗、高速度能完结特定规模语音辨认和动作指令的机器人体系的研发具有很大的实际意义。
2 体系硬件总体规划
体系的硬件功用是完结语音指令的收集和步进电机的驱动操控,为体系软件供给开发和调试渠道。如图1所示。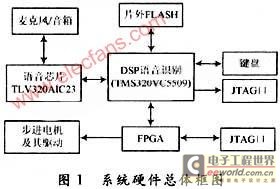
体系硬件分为语音信号的收集和播映,依据DSP的语音辨认,FPGA动作指令操控、步进电机及其驱动、DSP外接闪存芯片,JTAG口仿真调试和键盘操控几个部分。作业流程是麦克风将人的语音信号转化为模拟信号,在经过音频芯片TLV320AIC23量化转化成数字信号输入DSP.DSP完结辨认后,输出动作指令。
FPGA依据DSP输入的动作指令发生正确的正回转信号和精确的脉冲给步进电机驱动芯片,驱动芯片供给步进电机的驱动信号,操控步进电机的滚动。片外 FLASH用于存储体系程序和语音库并完结体系的上电加载。JTAG口用于与PC机进行联机在线仿真,键盘则用于参数调整和功用的切换。
3 语音辨认体系规划
3.1 语音信号的特色
语音信号的频率成分首要散布在300~3400Hz之间,依据采样定理挑选信号的采样率为8 kHz。语音信号的一个特色在于他的”短时性”,有时在一个短时段出现随机噪声的特性,而另一段体现周期信号的特性,或二者兼而有之。语音信号的特征是随时刻改变的,只要一段时刻内,信号才体现安稳共同的特征,一般来说短时段可取5~50 ms,因而语音信号的处理要树立在其”短时性”上[2],体系将语音信号帧长设为20 ms,帧移设为10 ms,则每帧数据为160×16 b。
3.2 语音信号的收集和播映
语音收集和播映芯片选用的是TI公司出产的TLV320AIC23B,TLV320AIC23B的模数转化(ADC)和数模转化(DAC)部件高度集成在芯片内部,芯片选用8 k采样率,单声道模拟信号输入,双声道输出。TLV320AIC23具有可编程特性,DSP可经过操控接口来修改该器材的操控寄存器,而且能够编译 SPI,I2C两种标准的接口,TLV320AIC23B与DSP5509的电路衔接如图2所示。
DSP选用I2C口对TLV320AIC23的寄存器进行设置。当MODE=O时,为I2C标准的接口,DSP选用主发送形式,经过I2C口对地址为 0000000~0001111的11个寄存器进行初始化。I2C形式下,数据是分为3个8 b写入的。而TLV320AIC23有7位地址和9位数据,也就是说,需要把数据项上面的最高位补充到第二个8 B中的最终一位。
MCBSP串口经过6个引脚CLKX,CLKR,FSX,FSR,DR和CX与TLV320AIC23相连。数据经MCBSP串口与外设的通讯经过DR和 DX引脚传输,操控同步信号则由CLKX,CLKR,FSX,FSR四个引脚完结。将MCBSP串口设置为DSP Mode形式,然后使串口的接纳器和发送器同步,而且由TLV320A%&&&&&%23的帧同步信号LRCIN,LRCOUT发动串口传输,一起将发送接纳的数据字长设定为32 b(左声道16 b,右声道16 b)单帧形式。
3.3 语音辨认程序模块的规划
为了完结机器人对非特定人语音指令的辨认,体系选用非特定人的孤立词辨认体系。非特定人的语音辨认是指语音模型由不同年纪、不同性别、不同口音的人进行练习,在辨认时不需要练习就能够辨认说话人的语音[2]。体系分为预加剧和加窗,短点检测,特征提取,与语音库的形式匹配和练习几个部分。
3.3.1 语音信号的预加剧和加窗
预加剧处理首要是去除声门鼓励和口鼻辐射的影响,预加剧数字滤波H(Z)=1一KZ-1,其间是为预加剧系数,挨近1,本体系中k取0.95。对语音序列X(n)进行预加剧,得到预加剧后的语音序列x(n):x(n)=X(n)一kX(n一1) (1)
体系选用一个有限长度的汉明窗在语音序列上进行滑动,用以截取帧长为20 ms,帧移设为10 ms的语音信号,选用汉明窗能够有用削减信号特征的丢掉。
3.3.2 端点检测
端点检测在词与词之间有满足时刻空隙的情况下检测出词的首末点,一般选用检测短时能量散布,方程为:
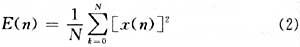
其间,x(n)为汉明窗截取语音序列,序列长度为160,所以N取160,为关于无音信号E(n)很小,而关于有音信号E(n)会敏捷增大为某一数值,由此能够区分词的起始点和完毕点。
3.3.3特征向量提取
特征向量是提取语音信号中的有用信息,用于进一步的剖析处理。现在常用的特征参数包含线性猜测倒谱系数LPCC、美尔倒谱系数MFCC等。语音信号特征向量选用Mel频率倒谱系数MFCC(Mel Frequency Cepstrum Coeficient的提取,MFCC参数是依据人的听觉特性的,他利用人听觉的临界带效应,选用MEL倒谱剖析技能对语音信号处理得到MEL倒谱系数矢量序列,用MEL倒谱系数表明输入语音的频谱。在语音频谱规模内设置若干个具有三角形或正弦形滤波特性的带通滤波器,然后将语音能量谱经过该滤波器组,求各个滤波器输出,对其取对数,并做离散余弦改换(DCT),即可得到MFCC系数。MFCC系数的改换式可简化为:

其间,i为三角滤波器的个数,本体系选P为16,F(k)为各个滤波器的输出数据,M为数据长度。
3.3.4 语音信号的形式匹配和练习
模型练习行将特征向量进行练习树立模板,形式匹配行将当时特征向量与语音库中的模板进行匹配得出成果。语音库的形式匹配和练习选用隐马尔可夫模型HMM (Hidden Markov Models),他是一种计算随机进程计算特性的概率模型一个两层随机进程,因为隐马尔可夫模型能够很好地描绘语音信号的非平稳性和可变性,因而得到广泛的运用。
HMM的根本算法有3种:Viterbi算法,前向一后向算法,Baum-Welch算法。本次规划运用Viterbi算法进行状况判别,将收集语音的特征向量与语音库的模型进行形式匹配。Baum-Welch算法用来处理语音信号的练习,因为模型的观测特征是帧间独立的,然后能够运用Baum- Welch算法进行HMM模型的练习。