导言
纠错码技能在数字通讯中具有重要作用,其间卷积码的编码办法,由于优秀的纠错功用被广泛使用,而Viterbi译码办法作为卷积码的一种最佳概率译码办法,关于卷积码的广泛使用具有重要价值。近年来,FPGA作为一种半定制电路,广泛使用于数字信号处理体系中,为Viterbi译码器的完结供给了有利条件。
点评Viterbi译码器功用的目标首要是译码速度和资源耗费,因而怎么减小译码时延、进步译码速度、下降资源耗费成为近年来研讨的热门。文献[5-6]经过改善文献[7-8]网格图的结构来下降译码时延、进步译码速率,文献[5]选用基二算法,文献[6]选用基四算法。其间基二算法的资源耗费小,但基二算法的数据处理才能比基四算法弱;基四算法处理数据才能比基二算法强,但基四算法的主频低,速度难以进步。文献[9-10]经过改善Viterbi的迭代办法进步译码速度,可是该办法杂乱度高,资源耗费大。文献[11]经过改善回溯结构来下降译码时延、进步译码速率,在文献[6]的基础上提出了依据滑窗流水的前向回溯基四算法,但该办法添加了冗余滑窗,资源耗费大,不适用于资源有限的场景。
为了使Viterbi译码算法可以在XC6SLX16-2CSG-324型FPGA上完结,并针对现在大多数改善算法在资源有限条件下难以统筹时延与资源耗费,本文在基二算法的基础上提出了一种改善算法。该算法在基二算法的基础上,对Viterbi译码器的衡量操控和幸存途径信息存储模块别离进行了改善,进步基二算法的数据处理才能,在资源有限条件下,可以有用简化译码器的完结结构,从而统筹时延与资源耗费,进步译码功用。
1、 改善Viterbi算法
1.1 算法原理
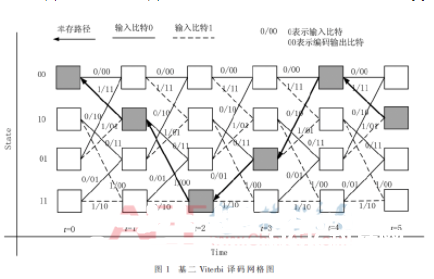
Viterbi算法是一种用于处理有限状况离散时间马尔科夫链的状况估量问题的优化算法。图1所示的基二网格图显现了卷积码的译码进程,详细描绘可拜见文献[1]。时间节点t表明第t个信息码元,Viterbi译码器从网格中找出最大似然途径。
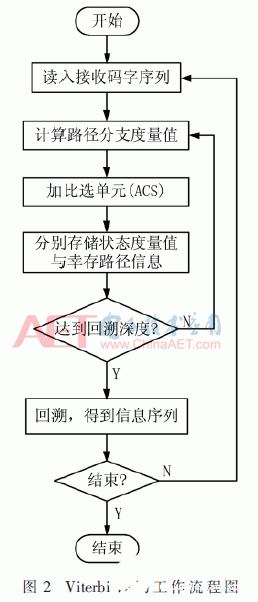
Viterbi译码器的作业流程如图2所示。将接收机[13]每一时间从信道接收到的信息序列与编码网格中一切的信息序列进行比较,依据软判定原理核算各分支途径衡量值,并与该分支下一时间进入状况的衡量值进行累加,保存进入每个状况的衡量值最小的分支途径和幸存途径信息,当到达回溯深度时,选出衡量值最小的状况作为开端逆向回溯的初始状况,依据幸存途径信息找到回溯的最大似然途径。
记(n0,k0,m)为卷积码编码器,该编码器共有2k0×m个状况,Viterbi译码器有必要具有相同的2k0×m个状况发生器,且每个状况有必要有一个存储途径衡量值的存储器和一个存储幸存途径信息的存储器,所以Viterbi译码器的杂乱度呈2k0×m指数添加。
1.2 算法改善的详细描绘
基二Viterbi译码器首要由分支衡量核算单元(BMU)、加比选单元(ACSU)、途径衡量存储单元(PMU)、幸存途径存储单元(SMU)、回溯单元(TBU)构成,体系框图如图3[3]所示。
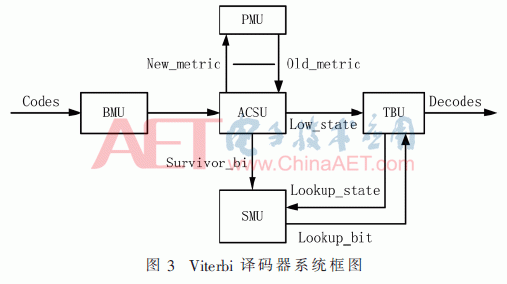
改善算法在基二算法的基础上,首要对ACSU中衡量操控结构和SMU的存储结构进行改善。记Si为状况i,PMi为状况Si的途径衡量累加值,τ为回溯深度(τ=L+m,L为信息码元数),Sub_bit为幸存途径信息,算法改善的详细描绘如下:

2 、理论剖析
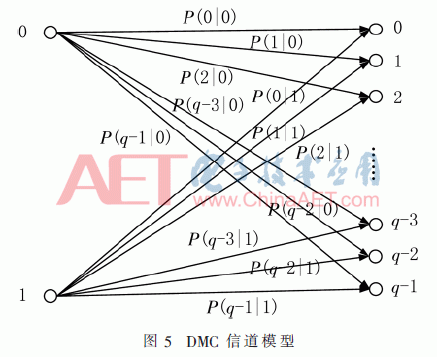
2.1 离散无记忆信道(DMC)模型
Viterbi译码算法的功用可由译码器输出的误码率进行剖析。由于改善算法选用软判定,这儿首要针对高斯白噪声(AWGN)下,BPSK调制的DMC信道模型依据不同回溯深度τ,τ=(5~10)m做误码率剖析。DMC信道模型如图5[1]所示,q为电平量化序列,左面表明信道输入为二进制0、1,右边表明信道输出为0~(q-1),p(q-1|0)表明输入为0输出为q-1的概率[1]。
依据信道编码定理,二进制对称信道(BSC)下,对某一给定的(n0,k0,m)卷积码,选用最大似然译码的Viterbi译码器发生过错事情的概率PE为[1]:

2.2 改善算法剖析
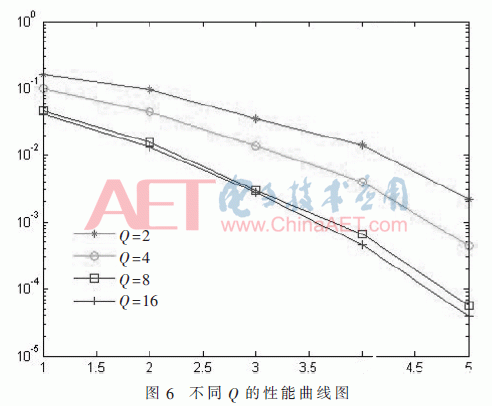
给定(2,1,4)卷积码,关于Viterbi的截尾译码器,回溯深度τ满意τ=(5~10)m即可[1],为节省衡量寄存器资源,本文挑选τ=20。然后在τ=20的情况下改动Q值,如图6所示。可以看出Q<8时判定增益添加比较显着,当Q>8后判定增益添加很慢。因而实践使用中一般选用八电平缓十六电平量化,译码器不会太杂乱,且有2~3 dB软判定增益[1]。因而挑选τ=20,Q=8能有用确保译码器功用。
3、仿真剖析
3.1 MATLAB仿真成果剖析
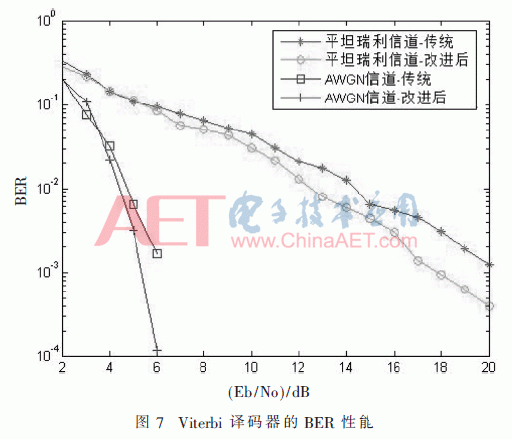
在MATLAB中,对Viterbi译码器别离在AWGN信道和平整瑞利式微信道中译码进行建模,给定(2,1,4)卷积码,当τ=20,Q=8时,对传统和改善后的译码器别离在AWGN信道和平整瑞利式微信道中进行仿真。该模型中,输入信道的信号为二进制相移键控(Binary Phase Shift Keying,BPSK)调制信号,信道的输出量化成八进制。误比特率(Bit Error Rate,BER)核算功用如图7所示。从BER功用来看,在AWGN信道中本文选用的Viterbi算法与传统的Viterbi算法比较,增益进步了约0.5 dB;在平整瑞利式微信道中本文选用的Viterbi算法与传统的Viterbi算法功用比较,在低信噪比时增益进步不显着,在高信噪比时增益进步了约1 dB。
3.2 ISE仿真成果剖析
针对τ=20,Q=8的(2,1,4)译码器,本文依据Verilog硬件描绘语言对各模块进行了RTL级描绘,并用ISE Design Suite 14.7进行了功用仿真。
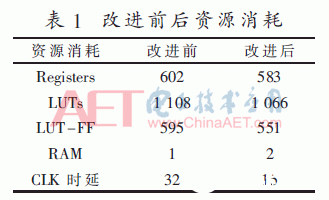
对改善前与改善后的Viterbi译码器进行ISE仿真,资源耗费与时延如表1所示。表中可以看出,选用本文提出的衡量操控办法和幸存途径存储结构的Viterbi译码器到达回溯深度后只需15个CLK推迟便可以译出第一个码元,选用传统的衡量操控与RE幸存途径存储结构的Viterbi译码器需求32个CLK推迟。改善后的译码器在速度上有了很大的进步,一起资源耗费也有了必定的节省。
Viterbi译码器的测验首要包含功用验证与译码器的纠错功用两部分。
首要进行功用验证,一切数据都是抱负的。由于τ=20,则译码器以20个数据为一组译码,本文的Viterbi译码器选用的是截尾译码,故使用MATLAB发生16个随机序列加上4个0组成一组信息序列为C1:11111101101110110000,经过编码器后的输出序列为C2:11_10_11_01_10_10_01_11_11_11_00_11_00_10_11_11_11_11_01_11,八电平量化后的序列为C3:111111_111000_111111_000111_111000_111000_000111_111111_111111_111111_000000_111111_000000_111000_111111_111111_111111_111111_000111_111111,将C3序列作为Viterbi译码器的输入,ISE仿真成果如图8所示。

图中Clk为码元时钟,code是C3序列,TB_flag为1表明到达回溯深度,code_in为译码输出成果:11111101101110110000,与C1序列彻底相同,故此译码器功用正确。
其次是纠错功用测验,在抱负数据中人为参加过错的搅扰信息。经核算,(2,1,4)译码器的df=7,故理论上此译码器可在5段接连译码中纠正3个随机过错。经测验,在20个接连码元段中参加3个随机过错码元,即误比特率为2.5%的情况下,译码器可以将过错彻底纠正。在20个接连码元段中参加4个随机过错码元,即误比特率为3.33%时不能将过错彻底纠正,但若过错码元之间距离≥5段码元时也可彻底纠正。理论值的纠错功用是在译码深度无限长时核算出来的,而无限长的译码深度在硬件上是无法完结的,因而在实践使用中的纠错功用会与理论值有必定的距离,但在实践通讯体系中,调制后经过信道传输的过错码率远未到达10-2这个数量级[1]。如图7所示,在AWGN信道中,只需信噪比大于4.5 dB,误码率就小于10-2这个数量级;在平整瑞利式微信道中,只需信噪比大于14 dB,误码率就小于10-2这个数量级,而实践通讯体系中信道的信噪比远远大于14 dB,因而本文改善的Viterbi译码器可以满意实践使用中的需求。
4 、定论
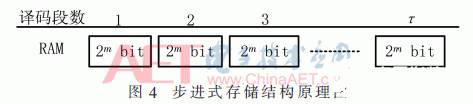
本规划首要针对ACS和SMU单元,简化译码器的结构,下降硬件完结的杂乱度,进步运算速度。在加比选单元的操控衡量部分,为了处理途径衡量数据溢出问题,本文提出了预界说存储衡量值寄存器容量法,减小了运算量,进步了译码速度。在幸存途径存储部分,优化了存储办法, 选用步进式存储办法,下降了译码器的功耗。回溯译码时,选用奇偶回溯法译码办法,依据幸存状况的奇偶性完结输出,减小了RAM的存储空间。仿真成果表明,本文的优化规划可以大大简化硬件电路的结构,在译码器的规划中具有使用价值。
责任编辑:gt